1. 导学
- 如何使用算法
- 如何评价算法的好坏
- 如何解决过拟合和欠拟合
- 如何调节算法的参数
- 如何验证算法的正确性
1.1 要求

1.2 如何使用算法
- 如何评价算法的好坏
- 如何解决过拟合和欠拟合
- 如何调节算法的参数
- 如何验证算法的正确性
2. 机器学习的数据
2.1 样本
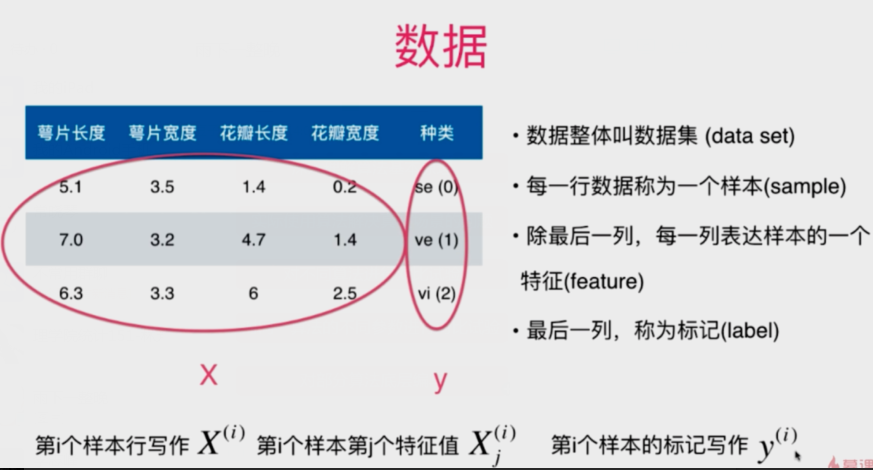
2.2 特征

2.3 特征空间


3. 机器学习分类
3.1 监督学习
给机器的训练数据拥有 “标记” 或者 “答案”
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
3.2 非监督学习
给机器的训练数据没有任何“标记” 或者 “答案”
对没有“标记”的数据进行分类--聚类分析
意义:
- 对数据进行降维处理
- 特征提取: 信用卡的信用评级 和 人的胖瘦无关?
- 特征压缩: PCA (不损失数据的情况下,将高维数据压缩成低维数据)
- 降维处理的意义:方便可视化
- 异常检测:
3.3 半监督学习
一部分数据有“标记” 或者 “答案“, 另一部分数据没有
更常见:各种原因产生的标记缺失
通常都先使用 无监督学习手段对数据做处理,之后使用 监督学习手段做模型的训练和预测
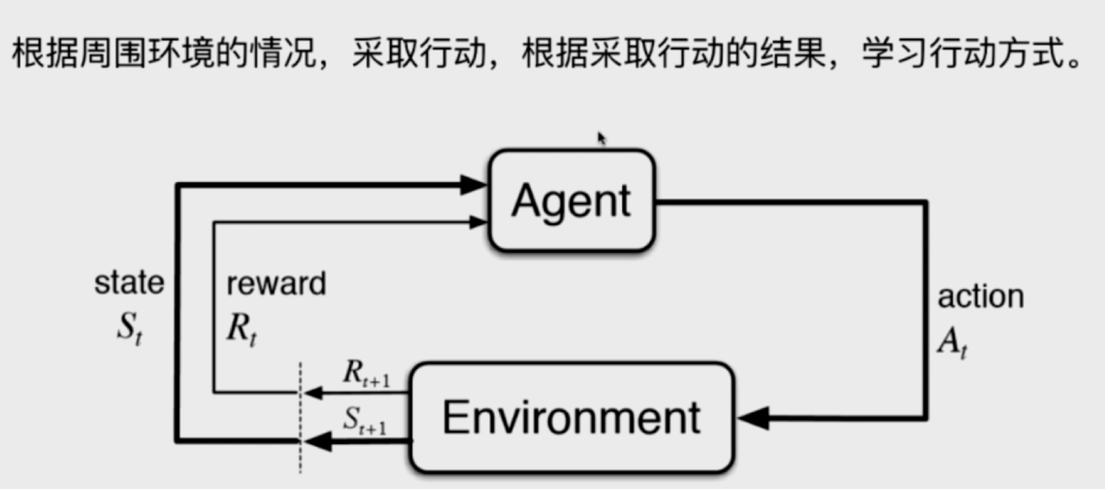
3.4 增强学习
- 无人驾驶
- 机器人
4. 机器学习的其他分类
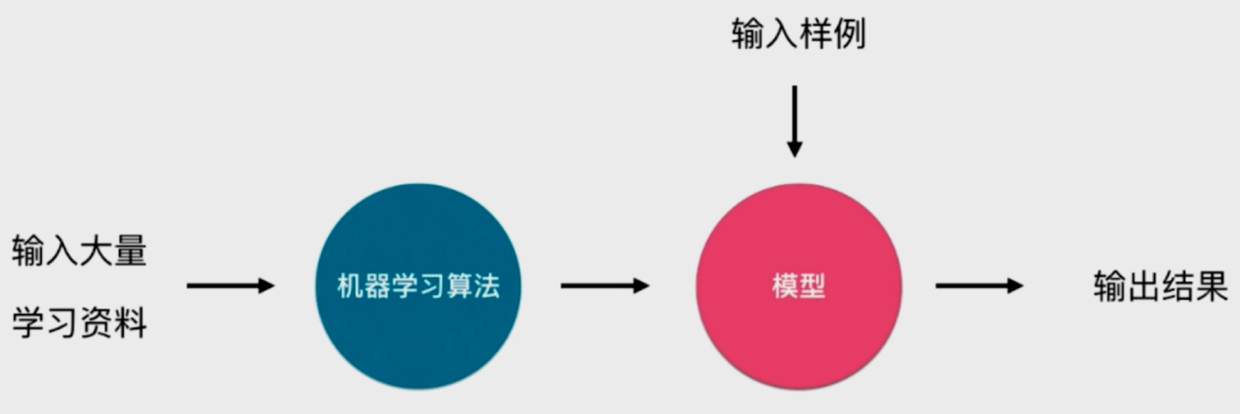
4.1 在线学习和批量学习
- 批量学习 Batch Learning(离线学习, 为主)
优点: 简单
- 问题:如何适应环境变化
- 解决方案:定时重新批量学习
缺点:每次重新批量学习,运算量巨大;
- 在线学习 Online Learning
优点:及时反映新的环境变化
- 问题:新的数据带来不会的变化
- 解决方案:需要加强对数据进行监控
其他:也适用于数据量巨大,完全无法批量学习的环境
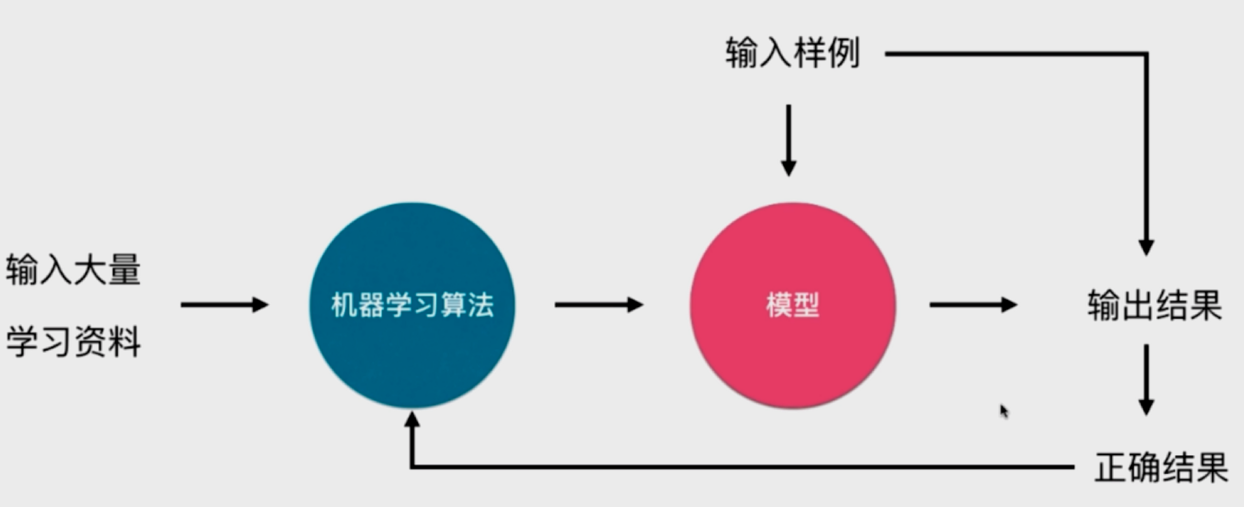
4.2 参数学习和非参数学习
- 参数学习 Parametric Learning
一旦学到参数,就不再需要原有的数据集
- 非参数学习 Nonparametric Learning
- 不对模型进行过多假设
- 非参数不等于没参数
5. 监督学习任务
5.1 分类任务
- 二分类
- 判断邮件是否为垃圾邮件
- 判断发给客户信用卡是否有风险
- 判断病患是良性肿瘤;恶性肿瘤
- 判断股票涨跌
- 多分类
- 手写数字识别
- 图像识别
- 判断发给客户信用卡的风险评级
- 2048游戏:转换为多分类,是否上移动,下移,左移等
- 围棋
- 无人车:根据环境信息,设置方向盘,油门、刹车
- 多分类的任务可以转换成二分类任务
- 多标签分类
一个图片分到多个类别

5.2 回归任务
- 结果是一个连续的数字的值,而非一个类别
- 房屋预测
- 市场分析
- 学生成绩
- 股票价格
- 一般情况下,回归任务可以简化成分类任务
- 无人驾驶
5.3 工作流程
6. jupyter notebook
6.1 快捷键
1 | run cell: ctrl + enter |
6.2 魔法命令
- %run:在 jupyter 中加载 .py文件代码
1 | %run ./magic.py # ./为文件路径 |
1 | import MagicTest.FirstML # 导入magictest的模块 |
1 | from MagicTest import FirstML |
- %timeit: 测试代码性能
1 | %timeit L = [i**2 for i in range(1000)] |
1 | %timeit L = [i**2 for i in range(10000000)] |
1 | %%timeit |
%time: 代码计时(不用重复)
1 | %time L = [i**2 for i in range(1000)] |
1 | %%time |
- 其他魔法命令
1 | %lsmagic |
1 | %run? # 查看文档 |
7. numpy和matplotlib
7.1 Numpy
7.11 Numpy.array
- 使用一:
1 | import numpy as np |
- 使用二:
1 | # 全为0,默认浮点型 |
- 查询相应文档
1 | np.random? |
7.12 numpy基本操作
1 | import numpy as np |
7.13 合并操作
1 | x = np.array([1, 2, 3]) |
7.14 分割操作
1 | x = np.arange(10) |
7.15 矩阵运算
- 矩阵对应元素间运算:
- A*2, A+2, np.exp(A)等都是对A中所有元素进行操作
- A+B, A*B, A/B: 都是矩阵元素之间对应运算
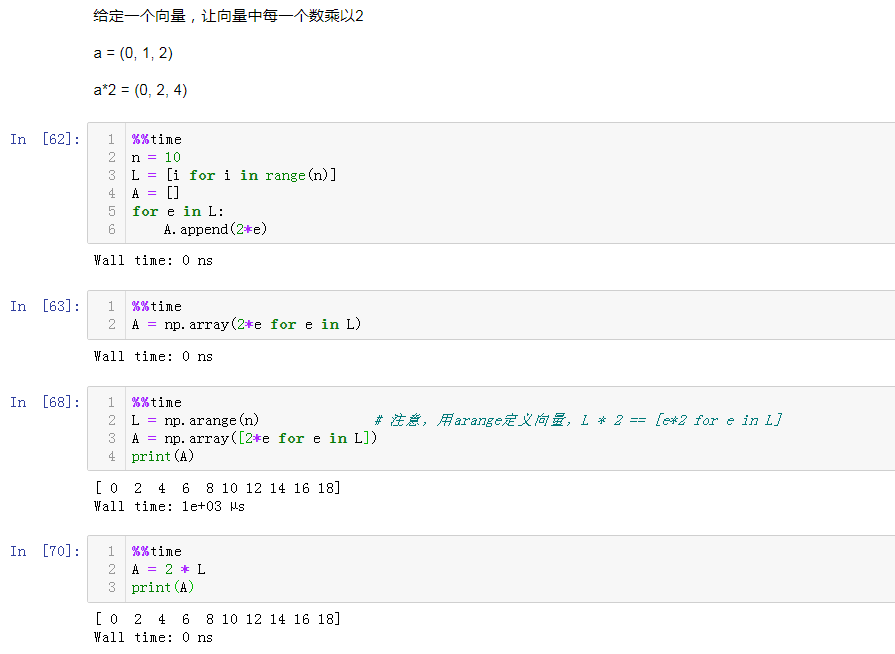
- 矩阵乘法:
- A.dot(B)
- 矩阵转置:
- A.T
- 矩阵的逆: \(A*A^{-1}=E\)
- np.linalg.inv(A) (方阵)
- 伪逆矩阵: np.linalg.pinv(x) (非方阵使用)
7.16 聚合操作
1 | import numpy as np |
- np.sum(A, axis=0) : 每一列的和
- np.sum(A, axis=1) : 每一行的和
- np.mean(X) : 均值
- np.median(X) : 中位数
- np.percentile(X, q=50) : 求 50% 的数
- np.var(X) : 方差
- np.std(X) : 标准差
7.17 索引
1 | np.min(x) |
7.18 排序
- np.sort(A, axis=1) :默认为1,按行排序
- axis=0 : 按列排序
np.argsort(x) : 按照索引排序
np.partition(x, 3) : 3前面的数字都比他小,后面的都比他大
7.19 FancyIndexing
- X[row, col]
- row, col 为索引组成的向量
1 | import numpy as np |
- 重要: 使用bool值
- a = [True, False, False, True]
- X[a] : 这种用法很常用
1 | print(x < 3) |
7.2 matplotlib
10. 评价分类结果
10.1 混淆矩阵Confusion Matrix
10.2 精准率和召回率
精准率:预测有100个人有癌症,在这些预测中,有多少是准确的。 \(precision = \frac{TP}{TP + FP}\)
- 需要的是精确度
召回率:实际上100人有癌症,我们的预测算法能从中正确的挑出多少。 \(recall = \frac{TP}{P} = \frac{TP}{TP + FN}\)
- 需要的是预测的范围,预测的多不多
1 | import numpy as np |
1 | 0.9755555555555555 |