classSolution: defisAlienSorted(self, words, order) -> bool: dic = {} for e in order: dic[e] = dic.get(e, 0) + order.index(e) wlen = len(words) flag = 0 for i in range(0, wlen): A = words[i] Alen = len(A) for j in range(i + 1, wlen): B = words[j] Blen = len(B) mlen = Alen if Alen < Blen else Blen # 小的长度 for k in range(mlen): # print(A[k], B[k]) if dic[A[k]] < dic[B[k]]: flag = 1 break elif dic[A[k]] > dic[B[k]]: returnFalse if flag: returnTrue else: returnFalse # return words == sorted(words, key=lambda w:[order.index(x) for x in w]) s = Solution()
classSolution: defmoveZeroes(self, nums) -> None: for e in nums[::]: if e == 0: nums.remove(e) nums.append(0) return nums s = Solution() print(s.moveZeroes([0, 1, 0, 3, 12]))
给出第一个词 first 和第二个词 second,考虑在某些文本 text 中可能以 "first second third" 形式出现的情况,其中 second 紧随 first 出现,third 紧随 second 出现。
对于每种这样的情况,将第三个词 "third" 添加到答案中,并返回答案。
示例 1:
1 2
输入:text = "alice is a good girl she is a good student", first = "a", second = "good" 输出:["girl","student"]
示例 2:
1 2
输入:text = "we will we will rock you", first = "we", second = "will" 输出:["we","rock"]
提示:
1 <= text.length <= 1000
text 由一些用空格分隔的单词组成,每个单词都由小写英文字母组成
1 <= first.length, second.length <= 10
first 和 second 由小写英文字母组成
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# -*- coding: utf-8 -*- classSolution: deffindOcurrences(self, text: str, first: str, second: str):#-> List[str]: words = text.split(' ') res = [] wlen = len(words) for i in range(0, wlen - 2): if words[i] == first and words[i + 1] == second: res.append(words[i + 2]) return res s = Solution() print(s.findOcurrences(text = "alice is a good girl she is a good student", first = "a", second = "good")) print(s.findOcurrences(text = "we will we will rock you", first = "we", second = "will"))
# -*- coding: utf-8 -*- classSolution: defkWeakestRows(self, mat, k: int):# -> List[int]: res = [] mlen = len(mat) for i in range(mlen): res.append((mat[i].count(1), i)) res.sort(key=lambda x:x[0]) res = [e[1] for e in res[:k]] return res s = Solution() print(s.kWeakestRows(mat = [[1,1,0,0,0], [1,1,1,1,0], [1,0,0,0,0], [1,1,0,0,0], [1,1,1,1,1]], k = 3)) print(s.kWeakestRows(mat = [[1,0,0,0], [1,1,1,1], [1,0,0,0], [1,0,0,0]], k = 2))
# -*- coding: utf-8 -*- classSolution: defprojectionArea(self, grid): x_area = 0 for x in grid: x = [e for e in x if e > 0] x_area += len(x) y_area = 0 elems = list(zip(*grid)) for e in elems: y_area += max(e) z_area = 0 for e in grid: z_area += max(e) areas = x_area + y_area + z_area return areas
s = Solution() print(s.projectionArea([[1,2], [3, 4]])) print(s.projectionArea([[1,0], [0,2]]))
# -*- coding: utf-8 -*- classSolution: deffib(self, N: int) -> int: if N == 0: return0 elif N == 1: return1 a, b = 0, 1 c = 0 for i in range(N-1): c = a + b a = b b = c return c s = Solution() print(s.fib(2)) print(s.fib(3)) print(s.fib(4))
# -*- coding: utf-8 -*- classSolution: defshortestToChar(self, S: str, C: str): index = [i for i in range(len(S)) if S[i] is C] res = [] slen = len(S) for i in range(slen): rmin = 100000 for j in index: dis = abs(i - j) if rmin > dis: rmin = dis res.append(rmin) print(res) return res s = Solution() print(s.shortestToChar(S = "loveleetcode", C = 'e'))
# -*- coding: utf-8 -*- classSolution: defcommonChars(self, A): res = list() for w in set(A[0]): # 遍历每个字符 cnt = [x.count(w) for x in A] # 每个单词的 字符w 数量 a = w * min(cnt) for i in a: # 防止不是全部都出现的,且分开添加 res.append(i) return res s = Solution() print(s.commonChars(["bella","label","roller"])) print(s.commonChars(["cool","lock","cook"]))
# -*- coding: utf-8 -*- classSolution: defshortestCompletingWord(self, licensePlate: str, words) -> str: import re awords = ''.join(re.findall('[a-zA-Z]+', licensePlate.lower())) # 按 长度,索引 排序 words = sorted(words, key=lambda x:(len(x), words.index(x))) for word in words: for e in awords: # print(awords, word, e, awords.count(e), word.count(e)) # 如果 word中没有e, awords中e数量 > word中e数量 if e notin word or awords.count(e) > word.count(e): break else: return word s = Solution() print(s.shortestCompletingWord(licensePlate = "1s3 PSt", words = ["step", "steps", "stripe", "stepple"])) print(s.shortestCompletingWord(licensePlate = "1s3 456", words = ["looks", "pest", "stew", "show"])) print(s.shortestCompletingWord("GrC8950", ["measure","other","every","base","according","level","meeting","none","marriage","rest"])) print(s.shortestCompletingWord("1s3 456", ["looks","pest","stew","show"]))
A -> 1 B -> 2 C -> 3 ... Z -> 26 AA -> 27 AB -> 28 ...
示例 1:
1 2
输入: "A" 输出: 1
示例 2:
1 2
输入: "AB" 输出: 28
示例 3:
1 2
输入: "ZY" 输出: 701
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# -*- coding: utf-8 -*- classSolution: deftitleToNumber(self, s: str) -> int: dic = {} for i in range(0, 26): dic[chr(ord('A')+i)] = i + 1 res = 0 slen = len(s) for i in range(slen): res += dic[s[i]] * 26**len(s[i+1:]) return res s = Solution() print(s.titleToNumber('A')) print(s.titleToNumber('ZY')) print(s.titleToNumber('AAA'))
classSolution: defconvertToTitle(self, n: int) -> str: dic = {} for i in range(0, 25): dic[i+1] = chr(ord('A')+i) dic[0] = 'Z' res = '' while n > 0: res += dic[n % 26] if n % 26 != 0: n = n // 26 else: n = (n - 26) // 26 return res[::-1] s = Solution() print(s.convertToTitle(701)) print(s.convertToTitle(52))
# -*- coding: utf-8 -*- classSolution: defsortArrayByParityII(self, A): Alen = len(A) res = [0] * Alen even, odd = 0, 1 for e in A: if e % 2 == 0: res[even] = e even = even + 2 else: res[odd] = e odd = odd + 2 print(res) return res s = Solution() print(s.sortArrayByParityII([4,2,5,7]))
# -*- coding: utf-8 -*- classSolution: defsortArrayByParity(self, A): i, j = 0, len(A)-1 while i < j: while i < j and A[i] % 2 == 0: i = i + 1 if i < j: t = A[i] while i < j and A[j] % 2 == 1: j = j - 1 if i < j: A[i] = A[j] A[j] = t print(A) return A s = Solution() print(s.sortArrayByParity([3, 1, 2, 4]))
# -*- coding: utf-8 -*- classSolution: defisUnique(self, astr: str): for e in astr: if astr.count(e) > 1: returnFalse returnTrue s = Solution() print(s.isUnique('leetcode')) print(s.isUnique('abc'))
# -*- coding: utf-8 -*- classSolution: defflipAndInvertImage(self, A): res = [] for li in A: li.reverse() rlen = len(li) for i in range(rlen): if li[i] == 0: li[i] = 1 else: li[i] = 0 res.append(li) return res s = Solution() print(s.flipAndInvertImage([[1,1,0],[1,0,1],[0,0,0]])) print(s.flipAndInvertImage([[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]]))
# -*- coding: utf-8 -*- classSolution: defoddCells(self, n, m, indices) -> int: ans = [[0]*m for i in range(n)] for b in indices: row = b[0] col = b[1] cnt = len(ans[0]) for i in range(cnt): ans[row][i] += 1 cnt = len(ans) for i in range(cnt): ans[i][col] += 1 ans = [e for ei in ans for e in ei if e % 2 == 1] return len(ans) s = Solution() print(s.oddCells(n = 2, m = 3, indices = [[0,1],[1,1]])) print(s.oddCells(n = 2, m = 2, indices = [[1,1],[0,0]])) print(s.oddCells(2, 2, [[1,1],[0,0]]))
# -*- coding: utf-8 -*- classSolution: deflastStoneWeight(self, stones) -> int: stones.sort(reverse=True) i = 0 while len(stones) > 1: x = stones[i+1] y = stones[i] if x == y: stones.remove(x) stones.remove(y) if x != y: stones.remove(x) stones.remove(y) stones.append(y - x) stones.sort(reverse=True)
if len(stones) > 0: return stones[0] else: return0 s = Solution() print(s.lastStoneWeight([2,7,4,1,8,1])) print(s.lastStoneWeight([5,1,8,10,7]))
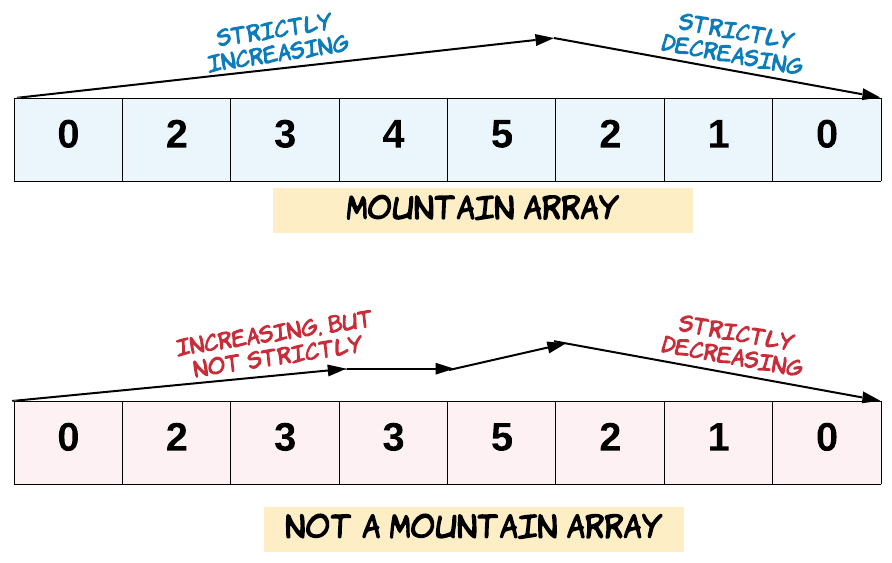
# -*- coding: utf-8 -*- classSolution: defvalidMountainArray(self, A) -> bool: i = 0 alen = len(A) while i < alen-1and A[i] < A[i + 1]: i = i + 1 if i == 0: returnFalse if i == alen-1: returnFalse while i < alen-1and A[i] > A[i + 1]: i = i + 1 if i == alen - 1: returnTrue else: returnFalse s = Solution() print(s.validMountainArray([2, 1])) print(s.validMountainArray([3, 5, 5])) print(s.validMountainArray([0, 3, 2, 1]))
# -*- coding: utf-8 -*- classSolution: deflemonadeChange(self, bills) -> bool: five, ten = 0, 0 for b in bills: if b == 5: five += 1 elif b == 10: ifnot five: returnFalse five -= 1 ten += 1 else: if ten and five: ten -= 1 five -= 1 elif five > 2: five -= 3 else: returnFalse returnTrue s = Solution()
# -*- coding: utf-8 -*- classSolution: defbackspaceCompare(self, S: str, T: str) -> bool: st1 = '' st2 = '' for e in S: if e != '#': st1 += e else: st1 = st1[:-1] for e in T: if e != '#': st2 += e else: st2 = st2[:-1] if st1 == st2: returnTrue else: returnFalse s = Solution() print(s.backspaceCompare(S = "ab##", T = "c#d#"))
输入: "I speak Goat Latin" 输出: "Imaa peaksmaaa oatGmaaaa atinLmaaaaa"
示例 2:
1 2
输入: "The quick brown fox jumped over the lazy dog" 输出: "heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa"
说明:
S 中仅包含大小写字母和空格。单词间有且仅有一个空格。
1 <= S.length <= 150。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# -*- coding: utf-8 -*-
classSolution: deftoGoatLatin(self, S: str) -> str: res = [] S = S.split() cnt = 1 for e in S: if e[0].lower() in ['a','e','i', 'o', 'u']: res.append(e + 'ma' + cnt*'a') else: res.append(e[1:] + e[0] + 'ma' + cnt*'a') cnt = cnt + 1 return' '.join(res) s = Solution() print(s.toGoatLatin("I speak Goat Latin")) print(s.toGoatLatin("The quick brown fox jumped over the lazy dog"))
# -*- coding: utf-8 -*- classSolution: defhasGroupsSizeX(self, deck) -> bool: import math dlen = len(deck) if dlen < 2: returnFalse
cnt = [deck.count(e) for e in deck]
mygcd = 9999999 for i in range(dlen - 1): t = math.gcd(cnt[i], cnt[i + 1]) if mygcd > t: mygcd = t if mygcd == 1: returnFalse for i in range(dlen - 1): if cnt[i] % mygcd != 0: returnFalse returnTrue s = Solution() print(s.hasGroupsSizeX([1,2,3,4,4,3,2,1])) print(s.hasGroupsSizeX([1,1,2,2,2,2])) print(s.hasGroupsSizeX([1,1,1,1,2,2,2,2,2,2]))
classSolution: defsubarraySum(self, nums, k: int) -> int: ans = 0 sum = 0 hash = {0 : 1} nlen = len(nums) for i in range(nlen): sum += nums[i] if ((sum - k) in hash): ans += hash[sum - k] # +1 if (sum in hash): # sum == 0 hash[sum] += 1# 如果sum 能加出 hash中的key, 则对应key的value+1 else: hash[sum] = 1
return ans s = Solution() print(s.subarraySum(nums = [1,1,1], k = 2)) print(s.subarraySum([28,54,7,-70,22,65,-6], 100))