基于python 从零实现NLP聊天机器人
聊天机器人综合介绍
NLP基础
- NLP领域


- NLP研究难点
单词边界界定
词义的消歧
不规范的输入
句法的模糊性
语言行为与计划
- 词处理
分词
- 词性标注(Part-of-speech tagging)
- 把分好的词一个一个分类(如, 动词, 形容词,名词)
- 实体识别
- 名词识别
- 词义消歧
- 联系上下文
- 语句处理
- 句法分析(Syntactic Analysis)
- “我去北京天安门”: 主谓分开
- 语义分析(Senmantic Analysis)
- 句子的理解
机器翻译
语音合成
- 篇章处理
- 自动文摘
- 机器读文章,写出摘要
- 统计语言模型
马尔科夫模型
隐马尔科夫模型
分词
把句子变成词
分词难点
- 分词标准
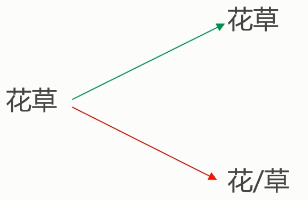
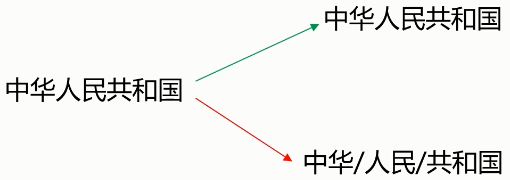
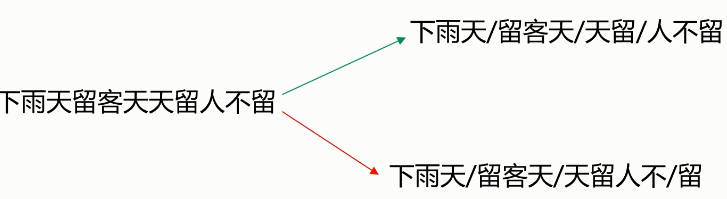
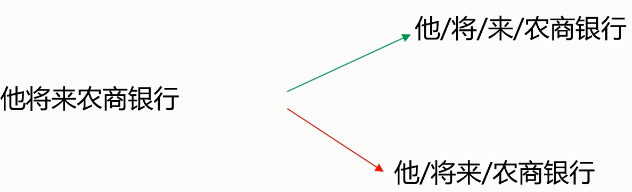
- 切分歧义(分词造成的语义分歧)
- 分词细粒度不同:
- 真正存在歧义的句子:
- 交集型的歧义
- 新词
- 给力,花呗,贸易战等等
- 分词的算法
- 基于词典的分词算法
- 正向最大匹配法
- 逆向最大匹配法
- 双向匹配分词
- 全切分路径选择
- 基于统计的分词算法
- HMM,隐马尔科夫模型
- CRF,条件随机场
- 深度学习
1 | import jieba |
TF-IDF



TF-IDF的作用
- 提取文本向量的特征
TF-IDF算法代码示例
1 | import numpy as np # 数值计算、矩阵运算、向量运算 |
- scikit-learn计算TF-IDF
1 | from sklearn.feature_extraction.text import TfidfTransformer |
1 | (0, 16) 0.4424621378947393 |
1 | from sklearn.feature_extraction.text import TfidfVectorizer |
1 | [[0. 0.52640543 0. 0. 0. 0.52640543 |
- NLTK计算TF-IDF
1 | from nltk.text import TextCollection |
NLTK

- 示例
1 | import nltk |
预料及词性标注
1 | # 中文词性标注, jieba |